數控機床網絡化控制系統的構建與關鍵技術研究

隨著工業4.0和智能制造的深入推進,數控機床作為制造業的核心裝備,其網絡化、智能化控制已成為技術發展的必然趨勢。基于網絡的數控機床控制技術,旨在通過集成先進的通信技術、計算技術和控制理論,實現機床的遠程監控、協同作業與高效管理,從而提升生產柔性、設備利用率和整體制造水平。
一、數控機床網絡控制系統的總體架構
一個典型的數控機床網絡控制系統通常采用分層分布式架構。最底層是設備層,由各類數控機床、傳感器和執行器構成,負責具體的加工任務。中間層是控制層,通常由工業計算機、可編程邏輯控制器(PLC)和嵌入式系統組成,負責對單臺或多臺機床進行實時控制與數據處理。最上層是管理層,通過企業局域網或互聯網,實現生產計劃下發、狀態監控、故障診斷與數據分析等高級功能。各層之間通過工業以太網、現場總線(如PROFIBUS、CANopen)或無線通信技術(如5G、Wi-Fi 6)進行高速、可靠的數據交換。
二、網絡控制系統的關鍵技術研究
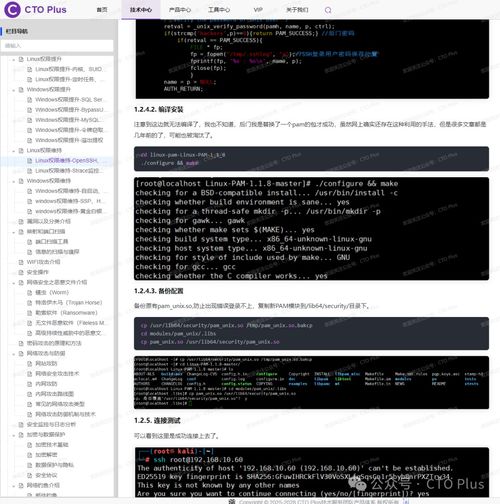
- 實時通信技術:數控加工對控制指令的實時性要求極高。研究重點在于開發或適配低延時、高確定性的工業網絡協議,如時間敏感網絡(TSN)、OPC UA over TSN等,確保指令精準同步與數據及時反饋。
- 遠程監控與診斷技術:借助物聯網(IoT)平臺,采集機床的運行狀態、加工參數、報警信息等數據。通過大數據分析和機器學習算法,實現預測性維護、故障根源分析和工藝參數優化,減少非計劃停機。
- 協同控制與調度技術:在多機床、多任務場景下,研究基于網絡的協同控制策略與動態調度算法。通過中央控制系統或分布式智能體,實現任務均衡分配、路徑協同規劃與碰撞避免,提升生產線整體效能。
- 信息安全技術:網絡化帶來了便利,也引入了安全風險。需構建縱深防御體系,包括網絡邊界防護、訪問控制、數據加密與完整性校驗,防止惡意攻擊和數據泄露,保障生產系統的安全穩定運行。
- 開放式與標準化接口:采用模塊化設計和標準化接口(如MTConnect),是實現不同廠商設備互聯互通、系統快速集成與功能擴展的基礎,也是構建柔性制造單元的關鍵。
三、技術開發與實踐挑戰
在實際開發中,面臨諸多挑戰。硬件層面,需要選擇或設計支持網絡功能的數控系統與通信模塊。軟件層面,需開發適配的驅動程序、中間件和應用軟件,實現數據的采集、解析、可視化與控制邏輯。系統集成時,需解決異構網絡融合、不同協議轉換等問題。網絡引入的通信延遲、數據包丟失等非確定性因素,對控制精度和穩定性提出了更高要求,需要通過改進控制算法(如網絡預測控制、魯棒控制)予以補償。
四、未來展望
數控機床的網絡控制將更加緊密地與數字孿生、云計算、邊緣計算和人工智能相結合。數字孿生技術可在虛擬空間對物理機床進行全生命周期映射與仿真,優化控制策略。云邊協同架構能將計算密集型任務(如工藝優化、復雜診斷)上云,而實時控制任務下沉至邊緣節點,實現算力與響應的最優平衡。人工智能的深度應用,將使控制系統具備更強的自主決策與自適應能力。
數控機床的網絡控制技術研究是一個多學科交叉的前沿領域,其發展與成熟將極大地推動制造業向數字化、網絡化、智能化轉型。持續攻克關鍵技術難題,構建安全、高效、開放的數控網絡生態系統,對于提升我國高端裝備制造的核心競爭力具有重要的戰略意義。
如若轉載,請注明出處:http://m.szyjf.cn/product/79.html
更新時間:2026-06-19 00:17:33